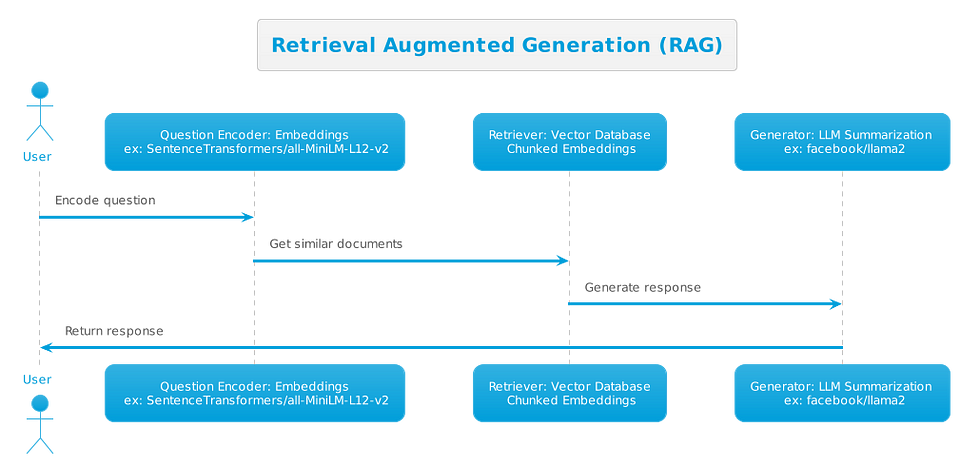
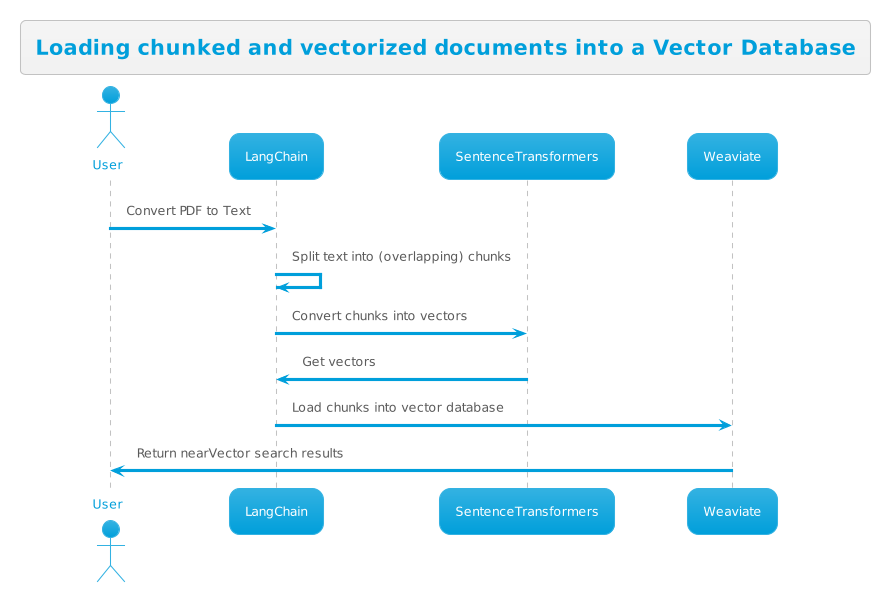
AI agents and tool integration are exciting — until you actually try to connect them. Different authentication systems (or none), fragmented documentation, and incompatible protocols quickly turn what should be simple integrations into debugging nightmares.
I've recently released ContextForge MCP Gateway as Open Source to solve this problem by sitting between your AI clients and tool servers, giving you an open source, clean, secure endpoint for everything — and supports both REST and MCP upstream and downstream protocols. If you find it useful or interesting, leave a star on GitHub!

The MCP Integration Problem
The Model Context Protocol promises to standardize how AI models call external tools, but the reality is messy. The ecosystem now has over 15,000 MCP-compatible servers, but they’re anything but uniform:
Transport chaos and incomplete implementations: Some servers only support STDIO, others stream over Server-Sent Events, and a few expose Streamable HTTP endpoints. They can’t talk to each other without custom adapters. And while the MCP specification evolves (now deprecating SSE) — MCP clients and servers are slow to catch up.
Security gaps: Many test servers skip authentication entirely or use weak schemes. Depending on what the client supports, you’ll want to either use a stdio wrapper, SSE + Bearer JWT auth, or full flown OAuth.
Writing new MCP Servers: Your existing API endpoints aren’t yet available as MCP Servers. You have to write new servers, and test them.
Everything lives somewhere different: Your prompt library runs on Server A, the vector database on Server B, and your custom tools on Server C. Managing URLs, keys, and retry logic across all of them becomes a full-time job.
How MCP Gateway Fixes This
Instead of handling retry logic and managing multiple MCP servers directly in your agent or client application, MCP Gateway centralizes all that complexity. You can create multiple virtual servers for different clients or use cases, each with their own tool configurations and access controls.
The MCP Gateway Wrapper allows you to connect to the gateway securely, using a JWT token, while exposing a local STDIO server.
The gateway acts as a smart proxy that normalizes everything behind a single endpoint:

One Consistent Interface
The gateway converts STDIO, SSE, and HTTP into consistent HTTPS+JSON-RPC, so your clients only need to know one protocol.
And your MCP Clients — Agents such as Langchain, Autogen, Crew.AI — or Visual Studio code plugins (ex: Microsoft Copilot) can connect over SSE + JWT Auth, or via STDIO locally (using mcpgateway-wrapper to connect securely to the Gateway).
Complete Tool Discovery and Debugging
The gateway automatically discovers all connected servers and presents every tool, prompt, and resource in one catalog.
Tools can be enabled, disabled and tested — and JSON Schema and tool description easily viewed.

Non-MCP API Support
Wrap any REST API endpoint and expose it as a fully-typed MCP tool with automatic retries and schema validation.
Built-in Observability
Every API call is timed and logged, so you can track performance and debug issues without external monitoring tools. Both per-tool, per server and aggregated metrics are available.

Getting Started
The gateway ships as a single Docker container or pip package with no external dependencies-just a local SQLite database.
Docker / Podman
docker run -d --name mcpgateway \
-p 4444:4444 \
-e HOST=0.0.0.0 \
-e JWT_SECRET_KEY=your-secret-key \
-e BASIC_AUTH_USER=admin \
-e BASIC_AUTH_PASSWORD=your-password \
ghcr.io/ibm/mcp-context-forge:v0.1.0Python Package
pip install mcp-contextforge-gateway
BASIC_AUTH_PASSWORD=password mcpgateway --host 127.0.0.1 --port 4444Once running, you’ll have access to http://localhost:4444 with:
- Admin Dashboard (
/admin) - Manage servers and tools through a web interface. - API Documentation (
/docs- and/redoc) Interactive Swagger documentation. - Version, Health and Configuration (
/versionand/health)— get version, configuration and debugging information. Requires auth (login to admin page first, or use as API to retrieve JSON). - JSON-RPC Endpoint (
/rpc) - RPC Endpoint. - Metrics (
/metrics) - Performance and usage statistics.
Detailed deployment across Containers, Docker, Compose, Kubernetes, OpenShift, Minikube, Helm, Code Engine, AWS and Azure is available through the project documentation page.
Integration with VS Code and GitHub Copilot
One of the most practical applications is connecting MCP Gateway to GitHub Copilot in VS Code. This gives Copilot access to all your tools through a single, secure connection.
Generate a JWT token and test it:
python -m mcpgateway.utils.create_jwt_token \
--username admin --exp 0 --secret my-test-key
curl -s -H "Authorization: Bearer $MCPGATEWAY_BEARER_TOKEN" \
http://localhost:4444/version | jqSpin up a couple of MCP Servers:
pip install uvenv
npx -y supergateway --stdio "uvenv run mcp-server-git"Add the MCP Servers to your gateway, under “Gateways”.

Now, create a Virtual Server under the Servers Catalog tab, adding just the tools you want to share with your MCP Clients.

Then, enable MCP support in VS Code by adding "chat.mcp.enabled": true to your GitHub Copilot Chat settings.json. Then add a mcp configuration block as described in VS Code the documentation:
{
"servers": {
"gateway": {
"type": "sse",
"url": "http://localhost:4444/servers/1/sse",
"headers": {
"Authorization": "Bearer YOUR_JWT_TOKEN"
}
}
}
}Press Ctrl + Alt + I to open Copilot Chat, and click on Tools. You’ll see all your gateway-managed tools available in the Tools panel:

Troubleshooting
You can use MCP Inspector to access the Global Tools catalog: http://localhost:4444/tools — then each of the individual virtual servers you’ve created. Ex: http://localhost:4444/servers/1/sse
npx @modelcontextprotocol/inspectorReal-World Impact
Instead of maintaining separate connections to a dozen different tool servers, each with its own authentication, error handling, and monitoring, you manage one gateway instance. When you need to add a new tool, you register it with the gateway rather than updating every client.
This architectural change becomes more valuable as your tool ecosystem grows. Whether you’re building a personal AI assistant or deploying enterprise-scale automation, MCP Gateway eliminates the integration overhead that typically consumes more time than the actual feature work.
The gateway is production-ready with Kubernetes support, Helm charts, and comprehensive monitoring. You can start with the simple Docker setup and scale up as needed.
Try It Out
- Source code: GitHub repository
- Documentation: Project docs
- Package: PyPI listing
The Model Context Protocol represents an important step toward standardized AI tool integration, but the implementation reality is still fragmented and the protocol and MCP ecosystem is going to evolve over time. MCP Gateway helps bridge that gap, turning different MCP servers into a unified, secure, and observable system.
Give it a try-you’ll spend less time on plumbing and more time building the AI experiences that matter.